How We Test VLMs for Image Extraction
Speed matters when you're scanning a syllabus or event flyer. We tested vision-language models (VLMs) from two providers (Global and China Region) to find the fastest one. This research helps us deliver the best experience for every user.
How We Tested
Each model received the same test image in English and Traditional Chinese. We measured network + inference time from API request to response, and verified every model returned the correct data. All tests ran from California over a wired connection.

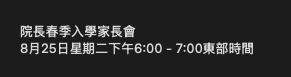
Google Gemini (Global)
| Model | English Image | Chinese Image |
|---|---|---|
| Gemini 3.1 Flash-Lite | 2.1s ✅ | 1.4s ✅ |
| Gemini 2.5 Flash-Lite | 1.4s ✅ | Failed ❌ |
| Gemini 2.5 Flash | 4.7s ✅ | 4.2s ✅ |
| Gemini 3.5 Flash | 6.0s ✅ | 6.2s ✅ |
| Gemini 3 Flash Preview | 6.1s ✅ | 8.5s ✅ |
| Gemini 2.5 Pro | 13.9s ✅ | 13.3s ✅ |
SiliconFlow (Hong Kong Server, China Region)
| Model | English Image | Chinese Image |
|---|---|---|
| Gemma 4 12B | 2.7s ✅ | 2.6s ✅ |
| Gemma 4 26B MoE | 3.7s ✅ | 7.2s ✅ |
| Qwen3.6 35B MoE | 9.9s ✅ | 7.5s ✅ |
| Qwen3-VL 8B | 4.4s ⚠️ | 8.2s ⚠️ |
| Gemma 4 31B | 6.5s ✅ | 9.3s ✅ |
| MiniMax M3 | 10.8s ✅ | 9.5s ✅ |
| Qwen3-VL 32B | 13.4s ✅ | 15.5s ✅ |
| Nex N2 Pro | 21.0s ✅ | 15.7s ✅ |
| GLM-5V Turbo | 9.1s ✅ | 19.8s ✅ |
| Qwen3.5 122B MoE | 124.3s ✅ | 22.7s ✅ |
| Qwen3.5 35B MoE | 75.7s ✅ | No items ❌ |
| Qwen3.5 397B MoE | 26.9s ✅ | 34.7s ✅ |
| Kimi K2.7 Code | 18.5s ✅ | 44.5s ✅ |
| Qwen3.5 9B | 60.7s ✅ | 48.8s ✅ |
| Qwen3.6 27B | 23.2s ✅ | 53.5s ✅ |
| Kimi K2.5 | 47.6s ✅ | 55.9s ✅ |
| Qwen3.5 27B | 29.1s ✅ | 77.3s ✅ |
| Kimi K2.6 | 74.5s ✅ | 78.8s ✅ |
| Qwen3-VL 32B Thinking | 110.5s ✅ | 105.7s ✅ |
⚠️ minor inaccuracy (wrong time format or value)